特征工程
引言
想象一下,你和朋友去看电影。电影还没结束,你朋友就说:“这电影肯定五星!”而你一脸懵:“怎么看出来的?”他说:“导演是大咖,演员演技在线,剧情节奏也好。”你朋友其实就是在“特征工程”——他从电影里挑出关键的“特征”,帮他判断电影好坏。
它就像是给模型“做饭”:从一堆杂乱的原始食材(数据)中,挑出有用的部分,洗干净、切好、调味,最后做成一道模型爱吃的“大餐”(特征)。说得简单点,特征工程就是通过数学和统计的方法,把原始数据变成模型能更好理解和学习的形式。
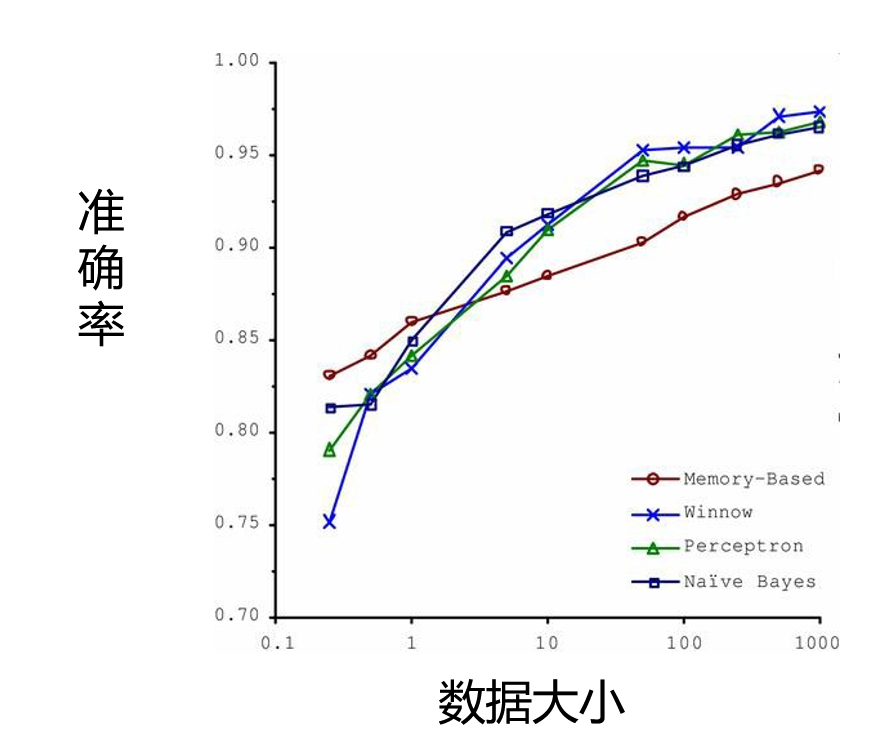
Memory-Based(基于记忆算法):红色圆圈。
Winnow:蓝色交叉线。
Perceptron(感知机):绿色三角形。
Naïve Bayes(朴素贝叶斯):蓝色方框。
1. 特征提取
特征提取是从原始数据中“创造”出一组新的、更具信息量的特征的过程。简单来说,就是把杂乱的原始数据“浓缩”成更有用的东西,让模型更容易理解。
通俗解释:
想象你在煮汤,原始数据是一堆食材(土豆、胡萝卜、肉),特征提取就像把这些食材熬成一碗浓汤,只保留精华部分。
目的:
- 把复杂或高维的数据(比如图片、文本)变成模型能处理的数值特征。
- 减少数据维度,降低计算复杂度。
- 挖掘数据的深层信息。
常见方法:
- 主成分分析(PCA):把多个相关特征“压缩”成几个新特征,保留主要信息。
- TF-IDF:从文本中提取词的重要性,转化为数值。
- 图像边缘检测:从图片像素中提取边缘或纹理特征。
例子:
假设你有一堆图片(原始数据是像素点),特征提取可以用算法找出图片里的边缘或颜色分布,这些新特征比原始像素更能帮模型识别内容。
2. 特征选择
定义:
特征选择是从已有特征中“挑选”出一部分最有用的子集,不改变特征本身,只是决定留下哪些、丢掉哪些。
通俗解释:
还是煮汤的比喻,特征选择不是熬汤,而是从一堆食材里挑出最有营养的(比如肉和胡萝卜),扔掉没用的(比如烂叶子)。
目的:
- 去掉无关、冗余或噪声特征,提升模型准确性。
- 减少特征数量,加快训练速度。
- 提高模型的可解释性。
常见方法:
- 过滤法:用统计指标(如相关系数)挑特征。
- 包装法:用模型测试哪个特征组合最好(比如递归特征消除)。
- 嵌入法:在训练中自动选特征(比如LASSO回归)。
例子:
预测房价时,数据有房屋面积、房间数、房子颜色等特征。特征选择发现面积和房间数对房价影响大,颜色没啥用,就扔掉颜色。
3. 特征构建
1. 归一化和标准化
1. 归一化(最大-最小标准化)
什么是归一化?
归一化就像把一堆大小不一的数字“挤”进一个统一的范围,通常是0到1。想象你有一堆考试成绩,有的满分是100,有的满分是50,归一化能让它们看起来都像是一个标准的分数范围,这样比较起来就公平了。
数学公式:
$x^* = \frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}}$
- $x$ 是原始数据的值。
- $x_{\text{min}}$ 是所有数据中最小的值。
- $x_{\text{max}}$ 是所有数据中最大的值。
- $x^*$ 是标准化后的新值。
怎么理解这个公式?
- 减去 $x_{\text{min}}$:把最小值移到0。
- 除以 $x_{\text{max}} - x_{\text{min}}$:把整个范围压缩到0到1之间。
- 结果:最小值变成0,最大值变成1,其他值按比例落在中间。
举个例子:
假设你的数据是 [10, 20, 30, 40, 50]:
- $x_{\text{min}} = 10$, $x_{\text{max}} = 50$。
- 对于 $x = 20$:
$x^* = \frac{20 - 10}{50 - 10} = \frac{10}{40} = 0.25$ - 结果:
[0, 0.25, 0.5, 0.75, 1]。
图片里说了什么?
- 归一化的目标是让不同特征(比如身高、体重)在同一个量纲下,避免因为数值范围差异太大而影响模型。
- 但它可能会改变数据的分布形状,比如原来分布很“扁平”的数据可能被“拉长”或“压缩”。
什么时候用?
当你的数据范围差别很大(比如一个特征是0-1000,另一个是0-1),或者模型(像神经网络)对数据尺度敏感时,归一化很管用。
2. Z-Score标准化
什么是Z-Score标准化?
Z-Score标准化是把数据“拉平”,让它围绕平均值分布,看起来更“标准”。它不会把数据硬塞进0到1,而是让数据的平均值变成0,标准差变成1。就像给每个数据打分,告诉你它离平均值有多远。
数学公式:
$x^* = \frac{x - \mu}{\sigma}$
- $x$ 是原始数据的值。
- $\mu$ 是数据的平均值(均值)。
- $\sigma$ 是数据的标准差(衡量数据分散程度)。
- $x^*$ 是标准化后的新值。
怎么理解这个公式?
- 减去 $\mu$:把数据中心移到0。
- 除以 $\sigma$:把数据的分散程度调整到1。
- 结果:数据变成“标准正态分布”的样子,均值是0,标准差是1。
举个例子:
假设你的数据是 [10, 20, 30, 40, 50]:
- 均值 $\mu = (10 + 20 + 30 + 40 + 50) / 5 = 30$。
- 标准差 $\sigma \approx 15.81$(通过计算得来)。
- 对于 $x = 20$:
$x^* = \frac{20 - 30}{15.81} = \frac{-10}{15.81} \approx -0.63$ - 结果:
[-1.26, -0.63, 0, 0.63, 1.26]。
图片里说了什么?
- Z-Score标准化让数据均值为0,标准差为1,方便在不同特征间比较。
- 它不会改变数据的分布形状,只是移动和缩放了一下(比如原来是正态分布的,还是正态分布)。
什么时候用?
当你的数据有明显的大小差异,或者模型(像线性回归)假设数据是标准化的,Z-Score就很合适。它对异常值也更稳健。
3. 两者的区别和联系
| 方面 | 归一化 | Z-Score标准化 |
|---|---|---|
| 目标范围 | 数据缩放到[0,1] | 均值为0,标准差为1 |
| 公式 | $\frac{x - x_{\text{min}}}{x_{\text{max}} - x_{\text{min}}}$ | $\frac{x - \mu}{\sigma}$ |
| 分布变化 | 可能改变分布形状(扩展/压缩) | 不改变分布形状 |
| 适用场景 | 需要统一范围的模型 | 需要比较距离或正态化的模型 |
图片里的观察:
- 归一化像“强行统一规格”,可能会让数据分布变形。
- Z-Score像“调整视角”,保持数据原本的样子,只是换了个标准来看。
4. 为什么要做数据标准化?
机器学习模型就像挑食的孩子,如果数据尺度差别太大(比如一个特征是0-1000,另一个是0-1),模型可能会“偏心”,只关注数值大的特征。标准化通过归一化或Z-Score,把所有特征拉到同一水平线上,让模型公平对待每个特征,提升预测效果。
实际意义举例:
- 预测房价时,面积(平米)和房间数(个)单位不同,归一化或Z-Score能让它们平等竞争。
- 在图像处理中,像素值(0-255)如果不标准化,可能让模型训练变慢或不稳定。
2. 特征二值化
目的是通过对数据进行处理,将数值型特征转化为二进制特征(0或1),从而优化数据以提升模型性能。
2. 什么是特征二值化?
特征二值化是一种将数值型数据转换为二进制数据(0或1)的技术。具体来说:
- 设定一个阈值(threshold)。
- 如果特征值大于或等于阈值,就标记为1。
- 如果特征值小于阈值,就标记为0。
通俗解释:
就像考试及格线是60分,成绩≥60分的标记为“及格”(1),<60分的标记为“不及格”(0)。这里的60就是阈值。
目的:
- 简化数据:将复杂的数值转化为简单的二进制形式。
- 突出特征的有无:某些场景下,特征是否超过某个值比具体数值更重要。
3. 图片中的代码示例
代码解释:
**
from sklearn.preprocessing import Binarizer**:从Scikit-learn的预处理模块中导入Binarizer类。**
Binarizer(threshold=3)**:创建一个二值化工具,设置阈值为3。.fit_transform(iris.data):将这个二值化操作应用到Iris数据集
- Iris数据集包含花瓣和花萼的长度/宽度等特征,单位是厘米。
- 对于每个特征值:≥3的变成1,<3的变成0。
举个例子:
假设Iris数据集中的某个特征值是 [1.5, 3.2, 4.0, 2.8],阈值设为3:
- 1.5 < 3 → 0
- 3.2 ≥ 3 → 1
- 4.0 ≥ 3 → 1
- 2.8 < 3 → 0
结果:[0, 1, 1, 0]。
注意:
图片中的阈值3只是一个示例。实际中,Iris数据集的特征值大多大于3(比如花瓣长度通常在1-6厘米之间),所以阈值3可能不是最优选择。阈值应根据具体问题和数据分布来设定。
4. 特征二值化的应用场景
- 简化模型:在某些情况下,模型不需要精确的数值,只需要知道特征是否超过某个关键点。比如在垃圾邮件检测中,一个词的出现次数超过某个值(比如3次)可能就足以判断它是重要的,而不需要具体次数。
- 减少计算复杂度:二值化后的0和1更简单,模型训练可能更快。
- 突出关键信息:比如在用户行为分析中,登录次数≥5次标记为“活跃”(1),<5次标记为“不活跃”(0)。
5. 特征二值化的优缺点
优点:
- 数据简化,易于处理。
- 可以突出特征是否达到某个阈值,适合某些分类问题。
缺点:
- 信息损失:把连续值变成0或1,丢掉了原始数据的细节。
- 阈值选择关键:选得不合适,可能影响模型效果。
3. 定性特征哑编码
定性特征哑编码(也称为独热编码,One-Hot Encoding)。它包含了一段Python代码,演示了如何使用Scikit-learn库中的OneHotEncoder类对数据进行哑编码。下面是对图片内容的详细解释,帮助你理解它的含义和作用。
1. 图片的主题和文本
标题
:定性特征哑编码
- 这表明图片的重点是介绍一种将定性(类别型)特征转化为数值形式的技术。
文本
:使用preprocessing库的OneHotEncoder类对数据进行哑编码的代码如下:
- 这部分提示我们,接下来会展示一段具体的代码示例,使用的工具是Scikit-learn中的
OneHotEncoder类。
- 这部分提示我们,接下来会展示一段具体的代码示例,使用的工具是Scikit-learn中的
2. 代码示例
代码逐步拆解:
from sklearn.preprocessing import OneHotEncoder- 从Scikit-learn的
preprocessing模块中导入OneHotEncoder类。这个类是专门用来做独热编码的工具。
- 从Scikit-learn的
iris.targetiris.targetlua复制原数据: [0, 1, 2] 编码后: [[1, 0, 0], [0, 1, 0], [0, 0, 1]]1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
是Iris数据集中的目标值,也就是花的类别标签。Iris数据集是一个经典的机器学习数据集,包含三种花的类别:
- 0:Setosa
- 1:Versicolor
- 2:Virginica
- 原始形式是一个一维数组,例如 `[0, 1, 2, 0, 1, ...]`,表示150个样本的类别。
- **`.reshape((-1,1))`**
- `OneHotEncoder`要求输入数据是二维的,但`iris.target`是一维数组。为了适配要求,这里用`reshape((-1,1))`将其变成一个二维数组(列向量)。
- `-1`表示自动计算行数(这里是150行),`1`表示1列。
- 转换后,数据从 `[0, 1, 2]` 变成 `[[0], [1], [2]]`。
- **`OneHotEncoder().fit_transform()`**
- `OneHotEncoder()`:创建一个独热编码的对象。
- `.fit_transform()`:对数据进行拟合(fit)和转换(transform),一步完成编码过程。
- 输出是哑编码后的结果,通常是一个稀疏矩阵(sparse matrix),表示每个样本的类别用二进制向量表示。
------
#### 3. 哑编码(独热编码)的原理
**什么是独热编码?**
独热编码是一种将类别型数据(比如“红”、“蓝”、“绿”)转化为数值形式的方法。它的核心思路是:
- 为每个类别创建一个单独的二进制特征(列)。
- 如果样本属于某个类别,该列值为1,其他列值为0。
**举个例子**:
Iris数据集的目标值有三种类别:0(Setosa)、1(Versicolor)、2(Virginica)。独热编码后:
- 类别0 → `[1, 0, 0]`
- 类别1 → `[0, 1, 0]`
- 类别2 → `[0, 0, 1]`
编码后,每个样本的类别被表示为一个三维向量,清楚地告诉模型“这是哪一类”。
**代码的实际效果**:
- 输入:`iris.target`,一个包含150个样本类别(0, 1, 2)的一维数组。
- 处理:通过`reshape((-1,1))`变成150行1列的二维数组,再用`OneHotEncoder`编码。
- 输出:一个150行3列的稀疏矩阵,每行是一个样本的独热编码向量。例如:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
------
#### 4. 为什么要做独热编码?
- **模型需求**:机器学习模型(比如线性回归、神经网络)只能处理数值数据,而不能直接理解类别型数据(比如“Setosa”)。独热编码把类别变成数字,让模型能用。
- **避免误解**:如果直接把类别编码为0、1、2,模型可能会认为2比1大,1比0大,误以为类别间有大小关系。独热编码用二进制向量避免了这种问题。
------
#### 5. 应用场景和注意事项
**应用场景**:
- **分类任务**:像Iris数据集这样,目标值是类别型的,需要独热编码。
- **特征处理**:数据中有类别型特征(比如性别、颜色),需要转为数值形式。
**注意事项**:
- **维度增加**:如果类别很多(比如100种颜色),独热编码会生成100列,增加数据维度,可能导致计算负担重。
- **稀疏矩阵**:`OneHotEncoder`默认返回稀疏矩阵格式(节省内存),实际使用时可能需要转成普通数组(用`.toarray()`)。
### 4. 分箱
给出了两种常见的分箱方法:**按区间分箱**和**按数量分箱**。下面是对图片内容的详细解释,帮助你理解它的含义和应用。
------
#### 1. 图片的主题
图片的核心主题是**数据分箱**,这是一种数据预处理技术,主要用于将连续型变量(比如成绩、年龄等)转化为离散的类别型特征。文字说明:
> 一般在建立分类模型时,需要对连续变量离散化,特别离散化后,模型会更稳定,降低了模型过拟合的风险。
**为什么要做分箱?**
- **模型稳定性**:离散化后的特征可以减少数据中的噪声影响,使模型更稳健。
- **降低过拟合**:将连续值分组后,模型不会过于关注具体的数值差异,从而提高泛化能力。
------
#### 2. 数据示例
图片中给出了一个具体的连续型数据——学生的成绩列表:
csharp
复制
[63, 64, 88, 71, 42, 60, 99, 70, 32, 88, 34, 69, 83, 52, 66, 92, 82, 58, 66, 41]
1 |
|
python复制bins = [0, 59, 70, 80, 90, 100]
score_cat = pd.cut(score_list, bins)
print(pd.value_counts(score_cat))
1 |
|
复制(59, 70] 7
(0, 59] 6
(80, 90] 4
(90, 100] 2
(70, 80] 1
1 |
|
python复制score_cat = pd.qcut(score_list, 5)
print(pd.value_counts(score_cat))
1 |
|
复制(31.999, 50.0] 4
(50.0, 63.6] 4
(63.6, 69.4] 4
(69.4, 84.0] 4
(84.0, 99.0] 4
**解释输出:**
- **(31.999, 50.0]**:包含4个最低的成绩,比如32、34、42、41。
- **(50.0, 63.6]**:包含接下来的4个成绩,比如52、58、60、63。
- **(63.6, 69.4]**:包含中间的4个成绩,比如64、66、66、69。
- **(69.4, 84.0]**:包含较高的4个成绩,比如70、71、82、83。
- **(84.0, 99.0]**:包含最高的4个成绩,比如88、88、92、99。
**特点:**
- 每个区间的数据量相等(这里都是4个),适合数据分布不均匀时,确保每组都有代表性。
- 区间宽度可能不同,比如(31.999, 50.0]跨度18,而(63.6, 69.4]只有5.8。
------
#### 5. 两种方法的对比
| **方面** | **按区间分箱 (`pd.cut`)** | **按数量分箱 (`pd.qcut`)** |
| ------------ | ---------------------------- | -------------------------- |
| **划分依据** | 手动设定的固定区间 | 自动按数据量均分 |
| **区间数量** | 不一定相等(比如7 vs 1) | 相等(这里都是4) |
| **区间宽度** | 可自定义,可能不均 | 自动调整,可能不均 |
| **适用场景** | 有明确业务规则(如成绩等级) | 数据分布未知,需等频分析 |
------
#### 6. 分箱的意义
- **离散化**:将连续的成绩(32到99)变成类别(比如“低分”、“中分”、“高分”),方便分类模型处理。
- **捕捉模式**:分组后,模型能更容易发现成绩分布的规律,而不是纠结于具体数值。
- **实际应用**:比如在信用评分中,把收入分箱成“低收入”、“中等收入”、“高收入”,帮助模型预测违约风险。
------
#### 7. 总结
这张图片通过一个成绩数据集,展示了数据分箱的两种方法:
- **按区间分箱 (`pd.cut`)**:根据手动设定的边界划分,适合有明确规则的场景。
- **按数量分箱 (`pd.qcut`)**:自动按数量均分,适合数据分布不明的场景。
### 5. 聚合特征构造
#### 1. 什么是聚合特征构造?
**定义**:
聚合特征构造是一种通过对多个特征进行**分组聚合**来创建新特征的方法。这些特征通常来自同一张表格,或者通过多张表格的联接(JOIN操作)得到的联合数据集。
**通俗解释**:
想象你有一张记录顾客购买情况的表格,里面有顾客ID、购买日期和购买金额等信息。聚合特征构造就像是按顾客ID把数据“打包”,然后算出每个顾客的平均购买金额、最高金额等统计数据,这些统计数据就是新的特征。
**图片中的描述**:
- “聚合特征构造主要通过对多个特征的分组聚合实现,这些特征通常来自同一张表或者多张表的联立。”
- 这说明聚合特征构造的核心是对数据进行分组,并从分组中提取有用的信息。
------
#### 2. 聚合特征构造的实现方式
**步骤**:
聚合特征构造通常基于**一对多的关联**(One-to-Many Relationship),具体分为两步:
1. **分组**:根据某个键(比如顾客ID)将数据分成若干组。
2. **计算统计量**:对每组数据计算一些统计指标,生成新特征。
**通俗例子**:
假设你有一张订单表:
| 顾客ID | 订单日期 | 订单金额 |
| ------ | ---------- | -------- |
| A | 2023-01-01 | 100 |
| A | 2023-02-01 | 200 |
| B | 2023-01-15 | 150 |
- **一对多关联**:顾客A有2条订单记录,顾客B有1条,体现了一(顾客)对多(订单)的关系。
- **分组**:按顾客ID分组,A组包含金额[100, 200],B组包含金额[150]。
- 计算统计量
:
- A的平均金额 = (100 + 200) / 2 = 150
- A的最大金额 = 200
- B的平均金额 = 150
- **新特征**:生成一张新表:
| 顾客ID | 平均金额 | 最大金额 |
| ------ | -------- | -------- |
| A | 150 | 200 |
| B | 150 | 150 |
**图片中的描述**:
- “聚合特征构造使用一对多的关联来对观测值分组,然后计算统计量。”
- 这清晰地概括了分组和统计的过程。
------
#### 3. 常见的统计量
图片列举了一些常见的分组统计量,这些统计量可以作为新特征,用于描述数据的特性:
- **中位数(Median)**:组内数据的中间值,比如A组[100, 200]的中位数是150。
- **算术平均数(Mean)**:组内数据的平均值,比如A组的平均金额是150。
- **众数(Mode)**:组内出现最频繁的值(如果数据量少,可能不适用)。
- **最大值(Max)**:组内最大的值,比如A组的最大金额是200。
- **最小值(Min)**:组内最小的值,比如A组的最小金额是100。
- **标准差(Standard Deviation)**:衡量组内数据的离散程度,反映波动大小。
- **方差(Variance)**:类似标准差,衡量数据的波动情况。
- **频数(Count)**:组内记录的数量,比如A组有2条记录,频数是2。
**实际应用**:
- 在电商中,可以用“平均购买金额”反映顾客的消费能力,用“购买频数”反映活跃度。
- 在金融中,可以用“交易金额的标准差”判断用户的消费稳定性。
------
#### 4. 聚合特征构造的意义
- **丰富特征**:从原始数据中挖掘更多信息,让模型能捕捉到更深层次的模式。
- **降维**:把多条记录汇总成几个统计量,减少数据量,提高计算效率。
- **捕捉趋势**:比如通过“最大金额”发现高端消费行为,通过“频数”发现用户忠诚度。
------
#### 5. 总结
这张图片简洁地介绍了**聚合特征构造**的概念和实现方式:
- **定义**:通过分组聚合从数据中创建新特征。
- **方法**:利用一对多关联分组,然后计算统计量。
- **统计量**:包括中位数、平均数、众数、最大值、最小值、标准差、方差和频数等。
- **价值**:提升模型性能,增强数据表达能力。
### 6. PCA
PCA 就像给数据找一个“最佳视角”。想象你有一堆点分布在三维空间(比如房屋的面积、房间数、楼层数),这些点散乱得像天上的星星。PCA 能找到一条线或一个平面,把这些点“投影”过去,让你用更少的维度(比如从3D变2D)看清楚它们的大致分布。
**核心目标**:
- 减少特征数量(降维)。
- 保留数据的主要信息(变化最大的部分)。
那它是怎么做到的呢?下面是 PCA 的数学实现步骤,用生活化的例子带你走一遍。
------
#### PCA 的数学实现步骤
##### **步骤 1:把数据“搬到原点”——中心化处理**
**做什么?**
我们先让数据的平均值变成0。怎么做呢?对每个特征(比如面积、房间数),算出它的平均值,然后从每个数据点里减掉这个平均值。
**数学公式:**
$X_{\text{centered}} = X - \mu$
- $X$ 是原始数据(比如一个表格,每行是一个房子,每列是一个特征)。
- $\mu$ 是每个特征的平均值(比如所有房子的平均面积)。
- $X_{\text{centered}}$ 是中心化后的数据。
**举个例子:**
假设有3个房子的面积数据:
- 原始数据:`[1500, 1800, 2100]`
- 平均值:$\mu = (1500 + 1800 + 2100) / 3 = 1800$
- 中心化后:`[1500-1800, 1800-1800, 2100-1800] = [-300, 0, 300]`
**为什么这样做?**
把数据移到原点(均值为0),就像把散乱的点都挪到坐标系中间,方便我们找它们变化的方向。
------
##### **步骤 2:看看数据怎么“散”——计算协方差矩阵**
**做什么?**
中心化后,我们要知道数据是怎么“散开”的。协方差矩阵就像一个“地图”,告诉你每个特征自己变了多少(方差),还有特征之间怎么一起变(协方差)。
**数学公式:**
$C = \frac{1}{n} \cdot X_{\text{centered}}^T \cdot X_{\text{centered}}$
- $n$ 是数据点的数量(比如3个房子)。
- $X_{\text{centered}}^T$ 是中心化数据的转置(行变列,列变行)。
- $C$ 是协方差矩阵。
**举个例子:**
假设有2个特征:面积和房间数,中心化后的数据是:
| 面积 | 房间数 |
| ---- | ------ |
| -300 | -1 |
| 0 | 0 |
| 300 | 1 |
- $X_{\text{centered}}$ 是一个 3×2 的矩阵。
- 计算
XcenteredT⋅XcenteredX_{\text{centered}}^T \cdot X_{\text{centered}}XcenteredT⋅Xcentered
,结果是一个 2×2 的矩阵,再除以
n=3n=3n=3
,得到:
C=[600002002000.6667]C = \begin{bmatrix} 60000 & 200 \\ 200 & 0.6667 \end{bmatrix}C=[600002002000.6667]
- 对角线:面积的方差(60000),房间数的方差(0.6667)。
- 非对角线:面积和房间数的协方差(200),说明它们有点相关。
**为什么这样做?**
协方差矩阵告诉我们数据在哪个方向变化最大,这些方向就是我们想要的主成分。
------
##### **步骤 3:找到“变化最大的方向”——特征值分解**
**做什么?**
对协方差矩阵做“特征值分解”,找出它的特征值和特征向量。
- **特征值(λ)**:告诉你每个方向的变化量(方差)有多大。
- **特征向量(v)**:告诉你这些方向具体是啥。
**数学公式:**
$C \cdot v = \lambda \cdot v$
- $C$ 是协方差矩阵。
- $v$ 是特征向量,$\lambda$ 是特征值。
**举个例子:**
对上面的协方差矩阵 $C$ 做分解,可能得到:
- 特征值:$\lambda_1 = 60001, \lambda_2 = 0.3333$
- 特征向量:
- $v_1 = [0.999, 0.003]$(第一个主成分方向)
- $v_2 = [-0.003, 0.999]$(第二个主成分方向)
**为什么这样做?**
- 特征值大的方向(比如 $\lambda_1 = 60001$)是数据变化最大的方向,信息最多。
- 特征向量是新坐标轴的方向,我们要用它们重新表示数据。
------
##### **步骤 4:挑最重要的方向,投影数据——降维**
**做什么?**
从特征值中挑最大的几个(比如前k个),用对应的特征向量把原始数据“投影”过去,得到低维数据。
**数学公式:**
$Y = X_{\text{centered}} \cdot V_k$
- $V_k$ 是前k个特征向量组成的矩阵(比如 2×k)。
- $Y$ 是降维后的数据(行数不变,列数变成k)。
**举个例子:**
- 假设我们只取第一个主成分($k=1$),$V_1 = [0.999, 0.003]$。
- 中心化数据 $X_{\text{centered}}$ 是 3×2 的矩阵:
$\begin{bmatrix} -300 & -1 \\ 0 & 0 \\ 300 & 1 \end{bmatrix}$
- 投影:$Y = X_{\text{centered}} \cdot V_1 = [-299.7, 0, 300.3]$
- 结果:原来是2维(面积和房间数),现在是1维。
**为什么这样做?**
- 挑最大的特征值对应的方向,能保留最多信息(比如这里保留了99.9%的方差)。
- 丢掉小的方向,降低维度,简化计算。
------
#### 一个完整的例子
假设我们有3个房子的数据:
| 面积 (平米) | 房间数 |
| ----------- | ------ |
| 1500 | 3 |
| 1800 | 4 |
| 2100 | 3 |
1. **中心化**:
- 面积均值:1800,房间数均值:3.33
- 中心化后:`[-300, -0.33], [0, 0.67], [300, -0.33]`
2. **协方差矩阵**:
$C = \begin{bmatrix} 60000 & 50 \\ 50 & 0.222 \end{bmatrix}$
3. **特征值分解**:
- 特征值:$\lambda_1 = 60000.2, \lambda_2 = 0.02$
- 特征向量:$v_1 = [0.999, 0.001], v_2 = [-0.001, 0.999]$
4. **投影**:
- 只取 $v_1$,新数据:`[-299.7, 0.67, 299.7]`
- 从2维降到1维,保留了几乎全部信息。
------
#### PCA 的意义
- **降维**:从一大堆特征变成几个关键特征,计算更快。
- **保留信息**:挑变化最大的方向,保证不丢关键东西。
- **应用**:比如把几百个特征降到2个,还能画图看看数据长啥样。
------
#### 总结
PCA 的数学实现就像一场“数据瘦身运动”:
1. **中心化**:把数据搬到原点。
2. **协方差矩阵**:看看数据怎么散。
3. **特征值分解**:找到变化最大的方向。
4. **投影**:把数据压到这些方向上,瘦身成功!
### 7. ICA
#### 1. ICA是什么?
**定义**:
独立成分分析(ICA)是一种通过线性变换从混合数据中提取独立成分的统计方法。它的目标是将观测到的混合信号分解成多个独立的源信号。
**通俗解释**:
想象你在鸡尾酒会上,房间里有很多人同时说话,几个麦克风录下了这些声音的混合信号。ICA就像一个“超级听力专家”,能从这些杂乱的录音中分辨出每个人的声音,把它们分开。
**核心思想**:
假设我们观测到的数据(如声音、图像)是由多个独立信号混合而成的,ICA通过数学方法找到一个变换,把这些混合信号“解混”,恢复出原始的独立信号。
------
#### 2. ICA的数学实现
ICA的核心是通过线性变换来实现信号分离,具体公式如下:
**基本公式**:
$\mathbf{z} = \mathbf{W} \cdot \mathbf{x}$
- $\mathbf{x}$:观测到的混合数据(输入数据),通常是一个矩阵,每一行是一个样本,每一列是一个特征。
- $\mathbf{W}$:权重矩阵(也叫解混矩阵),这是我们要通过算法求解的关键。
- $\mathbf{z}$:转换后的结果,表示提取出的独立成分,每一行是一个样本,每一列是一个独立的源信号。
**目标**:
找到一个合适的 $\mathbf{W}$,使得 $\mathbf{z}$ 中的各个成分($\mathbf{z}$ 的每一列)之间的**统计独立性**最大化。统计独立性比简单的“无关”(如PCA中的去相关性)更强,指的是各个成分之间没有任何统计上的依赖关系。
**假设**:
- 源信号是**非高斯分布**的(因为高斯信号混合后无法分离)。
- 源信号之间是**独立**的。
------
#### 3. ICA的具体流程
图片中提到,**PCA是ICA的预处理方法**。以下是ICA的完整流程,结合数学实现:
##### **步骤1:数据预处理——使用PCA降维**
- **为什么用PCA?**
- PCA可以去除特征间的相关性,为ICA提供更“干净”的数据(ICA假设源信号独立,而相关性会干扰这一假设)。
- PCA还能减少数据维度,降低计算复杂度。
- **数学实现**:
1. **中心化**:对输入数据 $\mathbf{x}$ 进行中心化,使每个特征的均值为0。
$\mathbf{x}_{\text{centered}} = \mathbf{x} - \text{mean}(\mathbf{x})$
2. **计算协方差矩阵**:
$\mathbf{C} = \frac{1}{n} \cdot \mathbf{x}_{\text{centered}}^T \cdot \mathbf{x}_{\text{centered}}$ 其中 $n$ 是样本数。
3. **特征值分解**:对 $\mathbf{C}$ 进行分解,得到特征值 $\lambda_i$ 和特征向量 $\mathbf{v}_i$。
$\mathbf{C} \cdot \mathbf{v}_i = \lambda_i \cdot \mathbf{v}_i$
4. 白化(Whitening)
:将数据投影到特征向量上,并除以特征值的平方根,使数据方差归一化。
xwhitened=E⋅D−1/2⋅ET⋅xcentered\mathbf{x}_{\text{whitened}} = \mathbf{E} \cdot \mathbf{D}^{-1/2} \cdot \mathbf{E}^T \cdot \mathbf{x}_{\text{centered}}xwhitened=E⋅D−1/2⋅ET⋅xcentered
- $\mathbf{E}$:特征向量矩阵。
- $\mathbf{D}$:特征值对角矩阵。
- **结果**:$\mathbf{x}_{\text{whitened}}$ 是白化后的数据,特征间无相关性,方差为1,作为ICA的输入。
##### **步骤2:ICA分离独立成分**
- **目标**:在白化数据 $\mathbf{x}_{\text{whitened}}$ 上找到解混矩阵 $\mathbf{W}$,使 $\mathbf{z} = \mathbf{W} \cdot \mathbf{x}_{\text{whitened}}$ 的各个成分独立。
- **独立性度量**:
- **互信息(Mutual Information)**:衡量变量间的依赖性,互信息越小,独立性越高。
$I(\mathbf{z}_i, \mathbf{z}_j) = H(\mathbf{z}_i) + H(\mathbf{z}_j) - H(\mathbf{z}_i, \mathbf{z}_j)$ 其中 $H$ 是熵,目标是让 $I = 0$。
- **负熵(Negentropy)**:衡量数据的非高斯性(因为独立信号通常是非高斯的)。
$J(\mathbf{z}) = H(\mathbf{z}_{\text{gaussian}}) - H(\mathbf{z})$ 负熵越大,非高斯性越强,独立性越好。
- **优化方法**:
使用迭代算法调整 $\mathbf{W}$,最大化独立性。常见算法包括:
- FastICA
:通过最大化负熵快速分离独立成分。
1. 随机初始化 $\mathbf{W}$。
2. 计算 $\mathbf{z} = \mathbf{W} \cdot \mathbf{x}_{\text{whitened}}$。
3. 更新 $\mathbf{W}$:
$\mathbf{W} \leftarrow E\{\mathbf{x}_{\text{whitened}} \cdot g(\mathbf{W} \cdot \mathbf{x}_{\text{whitened}})\} - E\{g'(\mathbf{W} \cdot \mathbf{x}_{\text{whitened}})\} \cdot \mathbf{W}$ 其中 $g$ 是非线性函数(如 $g(y) = \tanh(y)$),$E$ 是期望。
4. 正交化 $\mathbf{W}$(保持独立性),重复直到收敛。
- **Infomax**:通过最大化信息传输实现分离。
- **结果**:$\mathbf{z}$ 是分离出的独立成分。
------
#### 4. ICA与PCA的区别
- PCA(主成分分析)
:
- 目标:最大化数据的方差。
- 方法:找到方差最大的正交方向。
- 结果:去相关性,但不保证独立性。
- ICA
:
- 目标:最大化特征间的独立性。
- 方法:基于非高斯性和统计独立性。
- 结果:分离出独立的源信号。
**例子**:
如果混合信号是两个人的声音,PCA可能会找到声音的“主要变化方向”,但不能分开两个人;ICA则能直接分离出每个人的声音。
------
#### 5. 数学实现的例子
假设我们有2个混合信号($\mathbf{x}$,2维数据),来自2个独立源信号($\mathbf{s}$):
- $\mathbf{x}_1 = 0.5 \cdot \mathbf{s}_1 + 0.3 \cdot \mathbf{s}_2$
- $\mathbf{x}_2 = 0.2 \cdot \mathbf{s}_1 + 0.6 \cdot \mathbf{s}_2$
**目标**:找到 $\mathbf{W}$,使 $\mathbf{z} = \mathbf{W} \cdot \mathbf{x}$ 恢复 $\mathbf{s}$。
1. **预处理**:
- 中心化:减去 $\mathbf{x}$ 的均值。
- 白化:用PCA将 $\mathbf{x}$ 转换为无相关性的 $\mathbf{x}_{\text{whitened}}$。
2. **ICA计算**:
- 初始化 $\mathbf{W} = \begin{bmatrix} w_{11} & w_{12} \\ w_{21} & w_{22} \end{bmatrix}$。
- 用FastICA迭代优化 $\mathbf{W}$,最大化 $\mathbf{z}$ 的非高斯性。
- 结果可能是 $\mathbf{W} \approx \begin{bmatrix} 2 & -1 \\ -0.5 & 1.5 \end{bmatrix}$,使得 $\mathbf{z}_1 \approx \mathbf{s}_1$,$\mathbf{z}_2 \approx \mathbf{s}_2$。
------
#### 6. ICA的应用场景
- **信号分离**:从多个麦克风的混合录音中分离每个人的声音。
- **图像处理**:从混合图像中提取独立特征(如分离背景和前景)。
- **脑电图分析**:从EEG信号中分离独立的脑电波。
------
#### 7. 总结
这张图片介绍了ICA的基本概念和实现:
- **概念**:通过线性变换 $\mathbf{z} = \mathbf{W} \cdot \mathbf{x}$ 从混合数据中提取独立成分。
- **流程**:先用PCA预处理(降维和去相关),再用ICA分离独立信号。
- **数学实现**:中心化 → 白化 → 优化 $\mathbf{W}$(如FastICA)。
- **与PCA区别**:PCA关注方差,ICA关注独立性。

