| 符号 | 定义 | 在 PruneFL 中的角色 |
|---|---|---|
| ⊙ | 两个向量的逐元素乘积 | 用于掩码操作,例如将参数向量与掩码向量相乘,保留重要参数,剪枝不重要参数。 |
| n, N | 客户端索引(单个设备)、客户端总数 | 表示参与联邦学习的边缘设备,N 是设备总数,用于分布式训练和参数聚合。 |
| k, K | 迭代索引(通信轮次)、总迭代次数 | 表示联邦学习的通信轮次,k 是当前轮次,K 是训练总轮次。 |
| I | 本地迭代次数(每个客户端的 SGD 步骤数) | 客户端在本地数据上进行的参数更新次数,影响本地计算开销和模型收敛速度。 |
| pₙ | 客户端 n 的聚合权重 | 用于服务器聚合客户端参数时的加权平均,例如根据客户端数据量分配权重。 |
| m(k) | 第 k 次迭代中的权重掩码(所有客户端共享) | 动态剪枝的关键,掩码中 0 表示参数被剪枝,1 表示保留。通过自适应策略更新,减少模型大小和通信开销。 |
| wₙ(k) | 客户端 n 在第 k 次迭代时的本地参数 | 客户端本地训练后的模型参数,上传至服务器进行聚合。 |
| w(k) | 全局参数(加权平均) | 服务器聚合后的全局模型参数,下发至各客户端进行下一轮训练。 |
| w’ₙ(k), w’(k) | 剪枝后的参数 | 应用掩码后的稀疏参数,仅保留重要参数,用于减少计算和通信负载。 |
| gₙ(w) | 客户端 n 在参数 w 处的随机梯度(w为模型参数向量) | 本地 SGD 计算的梯度,用于更新本地参数。在剪枝中可能用于评估参数重要性。 |
| ∇Fₙ(w) | 客户端 n 在参数 w 处的期望梯度 | 理论上的平均梯度,与随机梯度相对,用于收敛性分析。 |
| ∇F(w) | 全局期望梯度 | 全局模型的梯度方向,指导参数更新。在剪枝中可能用于优化掩码选择策略。 |
模型剪枝也叫模型稀疏化,即将部分对网络贡献较小的特征剔除或者置0,稀疏化可以分为两类:权重稀疏化(将网络中某些权重值设为0或删除,通过L1正则化或剪枝技术)和结构稀疏化(神经元剪枝)。模型中可以被剪枝(稀疏)的对象通常为权重、神经元(激活函数)、梯度。可以认为模型稀疏或剪枝的方法为置0和删除,个人认为稀疏对应置0,剪枝对应删除。
1. 权重稀疏
通常认为权重的绝对值大小是一种重要的衡量指标,权重数值越大代表对网络的输出贡献也越大,反之则不重要,删去对网络的影响也较小。
通常通过L1、L2正则化来迫使一些权重趋向于0,将一些低于阈值的权重参数删除,反复迭代这个删除过程知道模型的规模和精度达到预期。因为即使移除绝对值接近0的权重也会导致推理精度的损失,所以通常在剪枝后需要再训练。剪枝常做的三段式工作:训练、剪枝、微调。
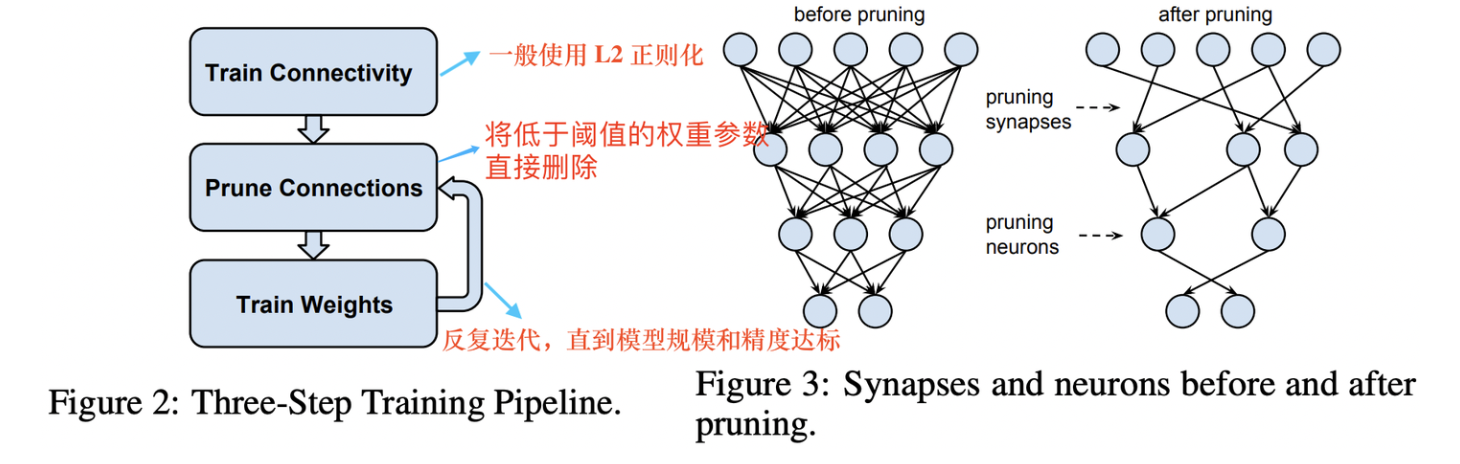
2. 神经元(激活函数)稀疏
首先这里给出现代网络常用激活函数ReLU函数的定义:ReLU(x)=max(0,x),负值的输入都会被置为0,这种方法也可以认为是通过激活函数的方法给网络进行稀疏化。同样池化操作也可以产生类似形式,受此现象启发,我们发现CNN中许多的神经元都是低激活状态的,因此我们认为零神经元可能是冗余的,可以在不影响整体网络精度的情况下移除,即对网络中的神经元进行剪枝,做移除神经元操作。
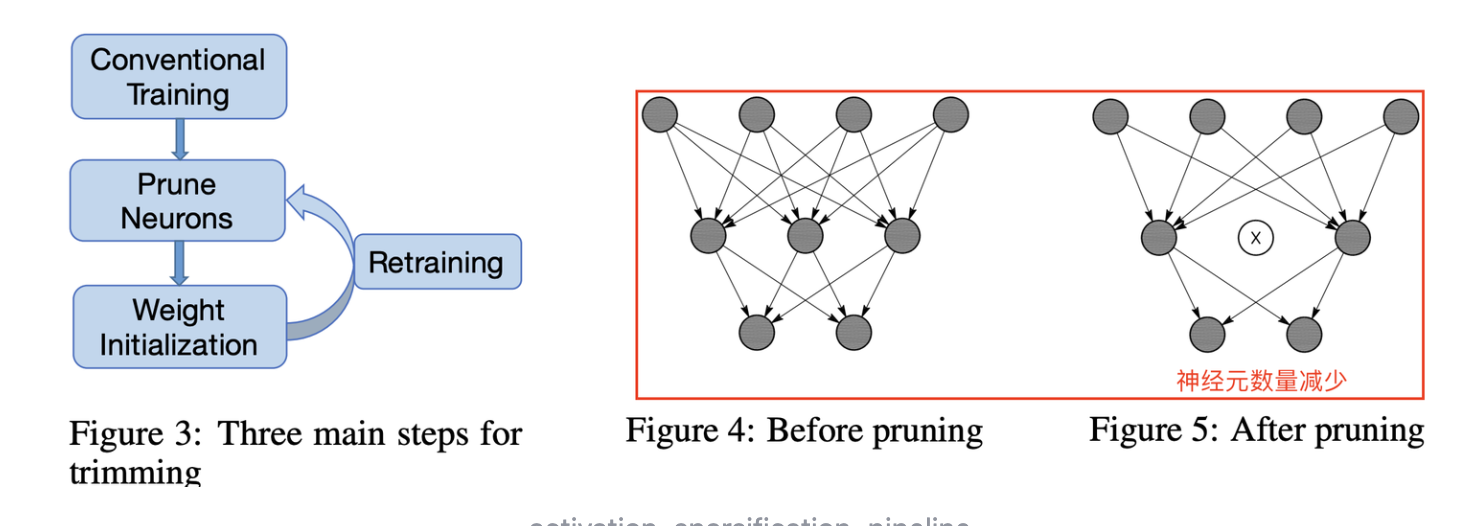
3. 梯度稀疏
通常采用选择固定比例的正负梯度更新或预设阈值。
深度梯度压缩:在梯度稀疏化基础上采用动量修正、本地梯度剪裁、动量因子遮蔽和 warm-up训练 4 种方法来做梯度压缩,从而减少分布式训练中的通信带宽。
神经网络的权重、激活和梯度稀疏性总结:
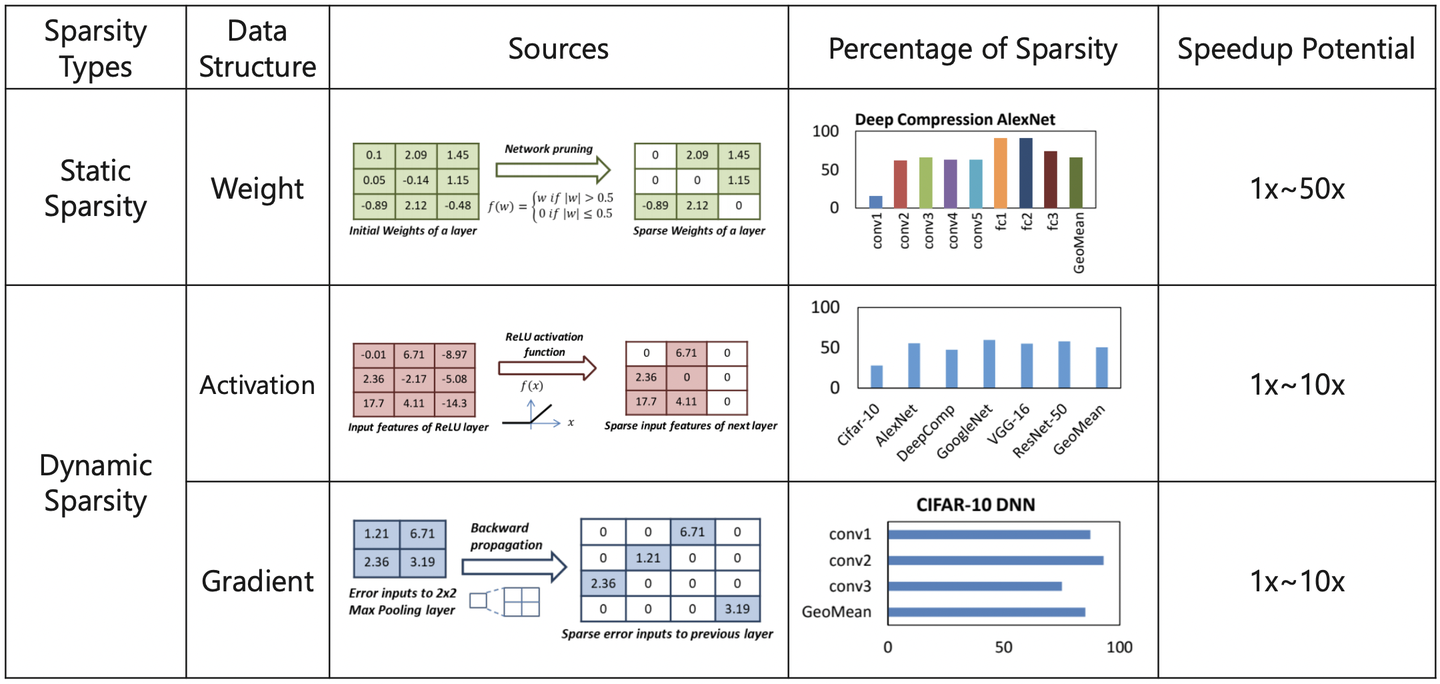
4. 结构化稀疏
分为Channel/Filter 剪枝或shape-wise 剪枝,即对网络的层数(滤波器)或网络的大小进行剪裁。channel 剪枝的工作是最多的,channel 剪枝和 filter 剪枝其实意义是一样的,一个过滤器移除了,对应输出 feature map 的一个通道自然也被移除,反之一样。
阶段式剪枝:可以弥补滤波器级剪枝的不足,如下图所示。
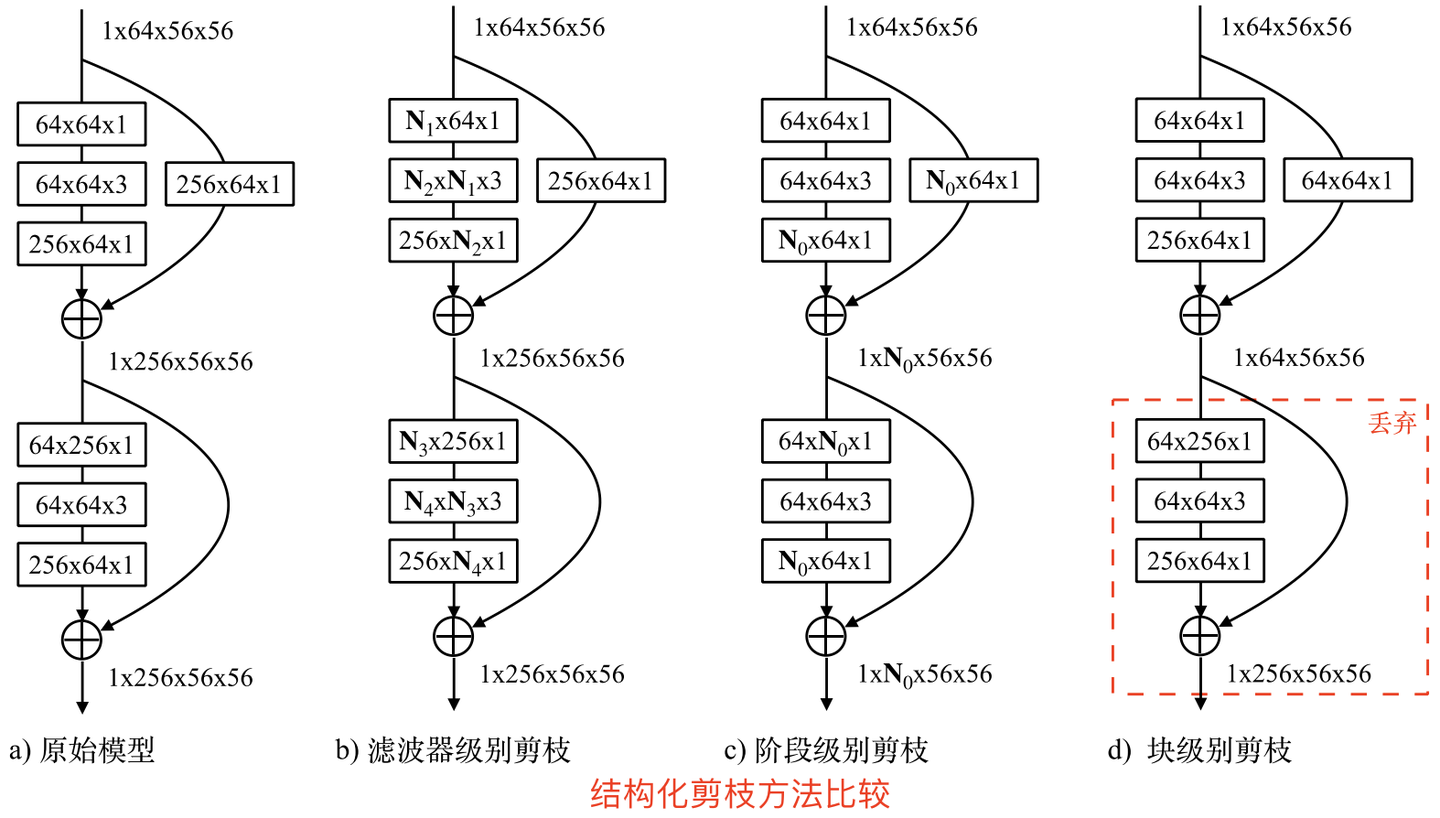
图中N1、N2等代表的是每一层实际保留的通道数,如a)原始模型有64个通道,b)中删减为了N1个。

